
最近刷新了下 Homelab,开始在 Homelab 中玩玩 Tanzu。去年 VMware 开源了 Tanzu Community Edition,正好利用这个机会装上配上 k10 和 VBR 玩一把。
硬件部分
我的环境由 2 台机器组成,一台是服役了 6 年多的 Dell Precision M4800,另外一台是新加入的 NUC11 猎豹峡谷。Dell 笔记本纯粹是在这个环境中打酱油的,而猎豹峡谷的配置如下:
- CPU:Intel(R) Core(TM) i5-1135G7 @ 2.40GHz
- 内存:ADATA 32GB×2 DDR4-3200
- 硬盘:aigo NVMe SSD P2000 1TB
- 网卡:Intel Corporation Ethernet Controller I225-V
软件部分
M4800 上,使用 DellEMC 的自定义 ESXi 镜像,从 DellEMC 的官网能够下载到,里面包含了所有 Dell 硬件的驱动。
NUC11 上安装 ESXi 最大的挑战来自于网卡驱动,这个网卡是 2.5GbE 的网卡,VMware 官方驱动中并不包含。不过大神们总有解决办法,社区版网卡驱动 戳这里 就能找到。
两台主机都安装 vSphere 7.0.3,vCenter 版本也是 7.0.3.
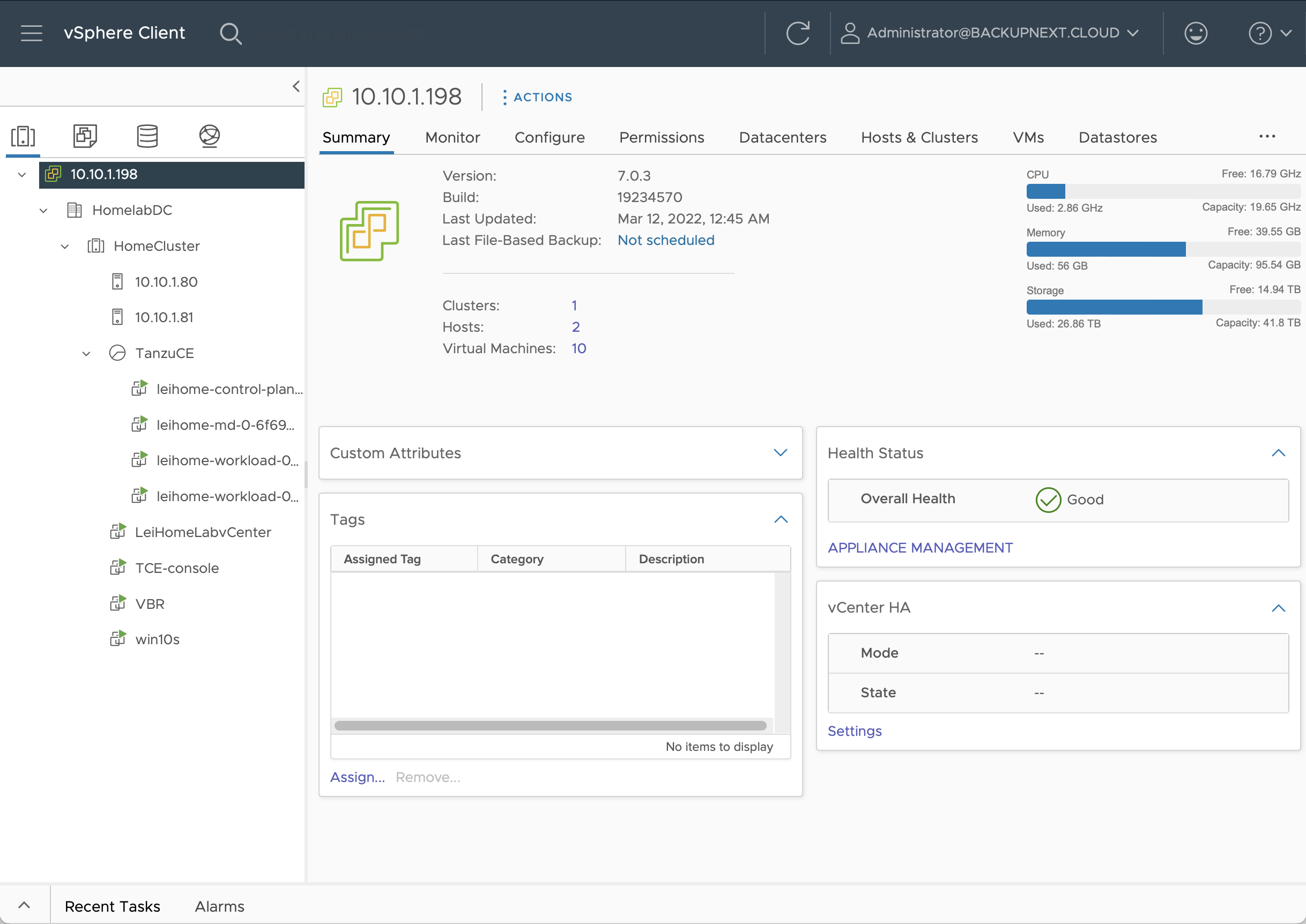
开动安装 TCE
环境准备
首先我需要一个控制台来安装并操作 TCE,TCE 的官方手册 上提供了 macOS、Linux 和 Windows 的三种平台安装。我选择在我的环境中安装一台 Ubuntu 20.04 LTS 的虚拟机来安装 Tanzu CLI 软件。
这台 Ubuntu,并不是一台最小化安装的普通 Ubuntu,需要另外准备以下环境:
-
安装 Docker,并配置 non-root 用户使用 Docker。配置方法很简单,只需要使用 non-root 用户,在安装完 docker 之后,按顺序执行下列命令即可。
## 1. 先加 docker 组 k10@tceconsole:~$ sudo groupadd docker ## 2. 把当前用户加到 docker 组里 k10@tceconsole:~$ sudo usermod -aG docker $USER ## 3. 接下去最好注销后重新登录,或者直接用下面的命令激活 $ newgrp docker ## 4. 试试 docker 命令,是否正常 k10@tceconsole:~$ docker run hello-world -
安装 kubectl,这个没啥特别,根据官网指引或者其他的说明直接安装即可。
有了这些条件后,就可以使用 TCE 官网手册中的安装方法来安装 Tanzu CLI 了
在 Tanzu CLI 安装好之后,还需要从 VMware 官网 下载 OVA 镜像,这个镜像是用来在 vSphere 中部署 k8s node 的,我选择了ubuntu-2004-kube-v1.21.5+vmware.1-tkg.1-12483545147728596280-tce-010.ova。
下载完成后,在 vSphere 中导入这个 ova,并立刻将这个 ova 转换成模板,如下图在 vSphere 中可以看到这样的状态即可:
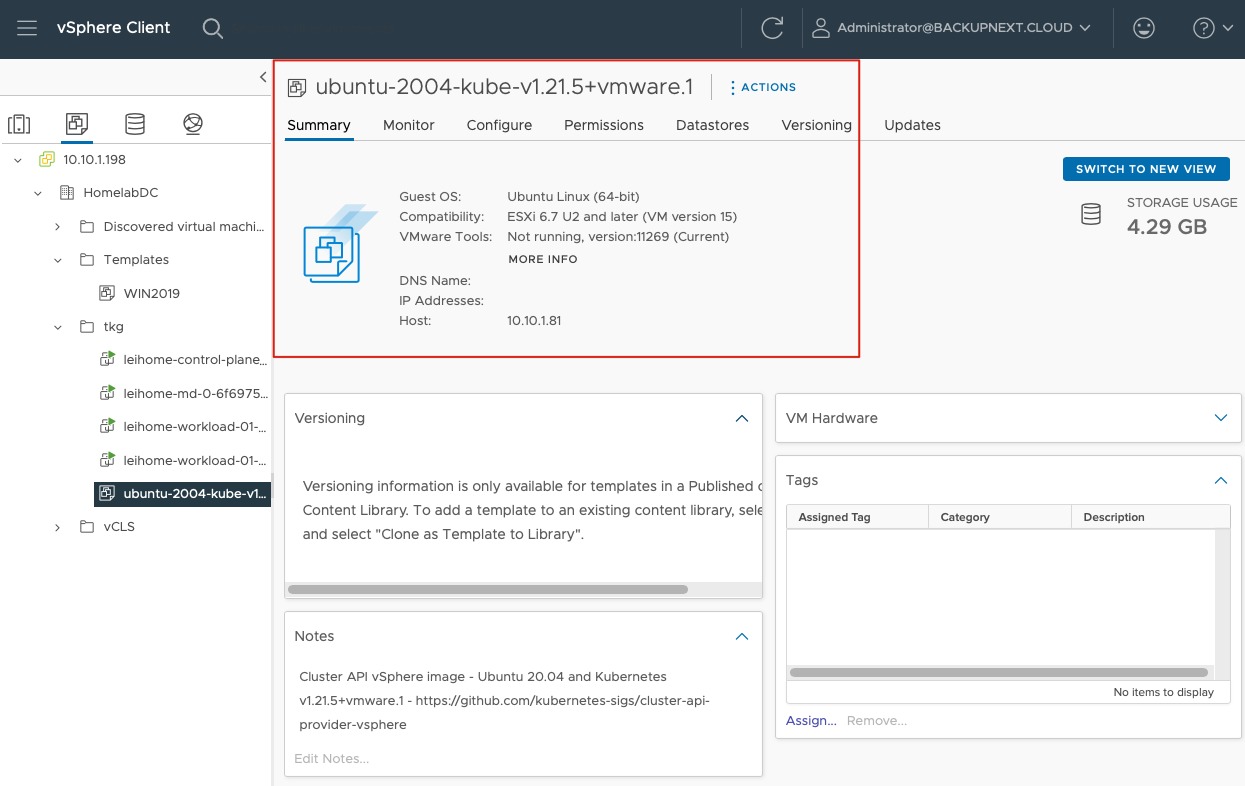
另外,我还要在我的环境中配置一个 DHCP 服务器,在部署集群时,TCE 必须依赖 DHCP 服务才能完成所有工作。
最后,是用下面的命令准备图形化安装第一步要用的 ssh public key
## 创建一个 SSH 密钥对
k10@tceconsole:~$ ssh-keygen -t rsa -b 4096 -C "administrator@backupnext.cloud"
## 获取下这个公钥备用
k10@tceconsole:~$ cat .ssh/id_rsa.pub
部署管理集群
TCE 和其他 Tanzu 一样,都由管理集群(Management Cluster)和工作负载集群(Workload Cluster)组成,我在我的环境中首先需要配置一个管理集群,配置启动方法非常简单,只需要运行下面的命令即可:
k10@tceconsole:~$ tanzu management-cluster create --ui --bind 0.0.0.0:8080 --browser none
命令运行后,我在我本地的浏览器中,打开http://<ubuntuip>:8080/ 就可以进入 Tanzu 安装向导图形界面了。
- 选择部署平台,VMware vSphere
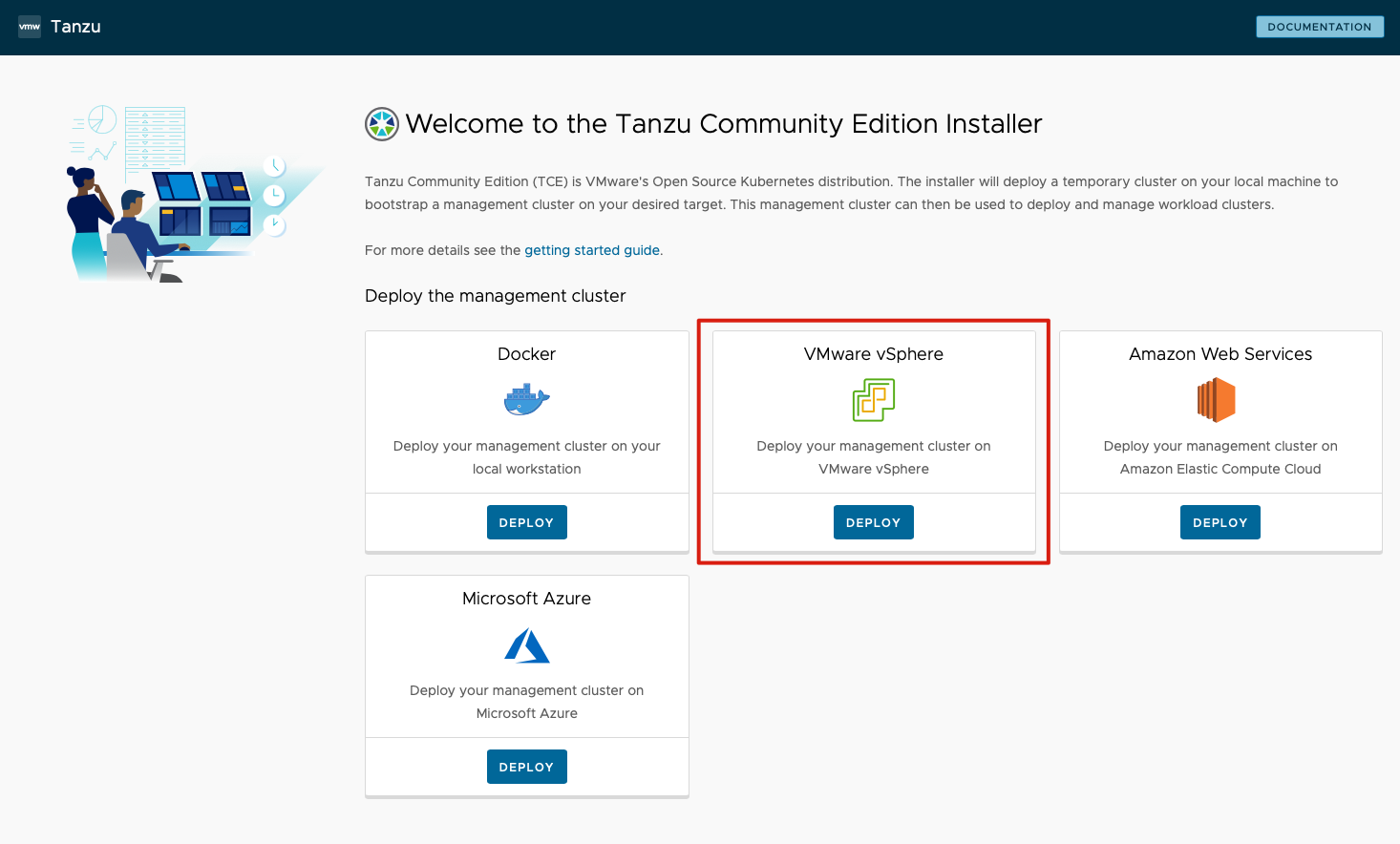
- 填入 vCenter 信息并连接,这里连接后,需要将前面准备好的 SSH 公钥填入到 SSH Public Key 框中。
- 设置管理集群信息,我选择了 Development 模式,这样在我的小 Lab 中只需要一台 Control Plane 节点,并且我将 Instance Type 选择了 small 的最小配置。我填写了 Management Cluster Name 为
leihome,启用了 Machine Health Checks。Control Plane Endpoint Provider 选择 Kube-vip,指定 Control Plane Endpoint 地址为 10.10.1.182,设定了 Worker Node Instance Type 为 Small,Audit Logging 为不 Enable。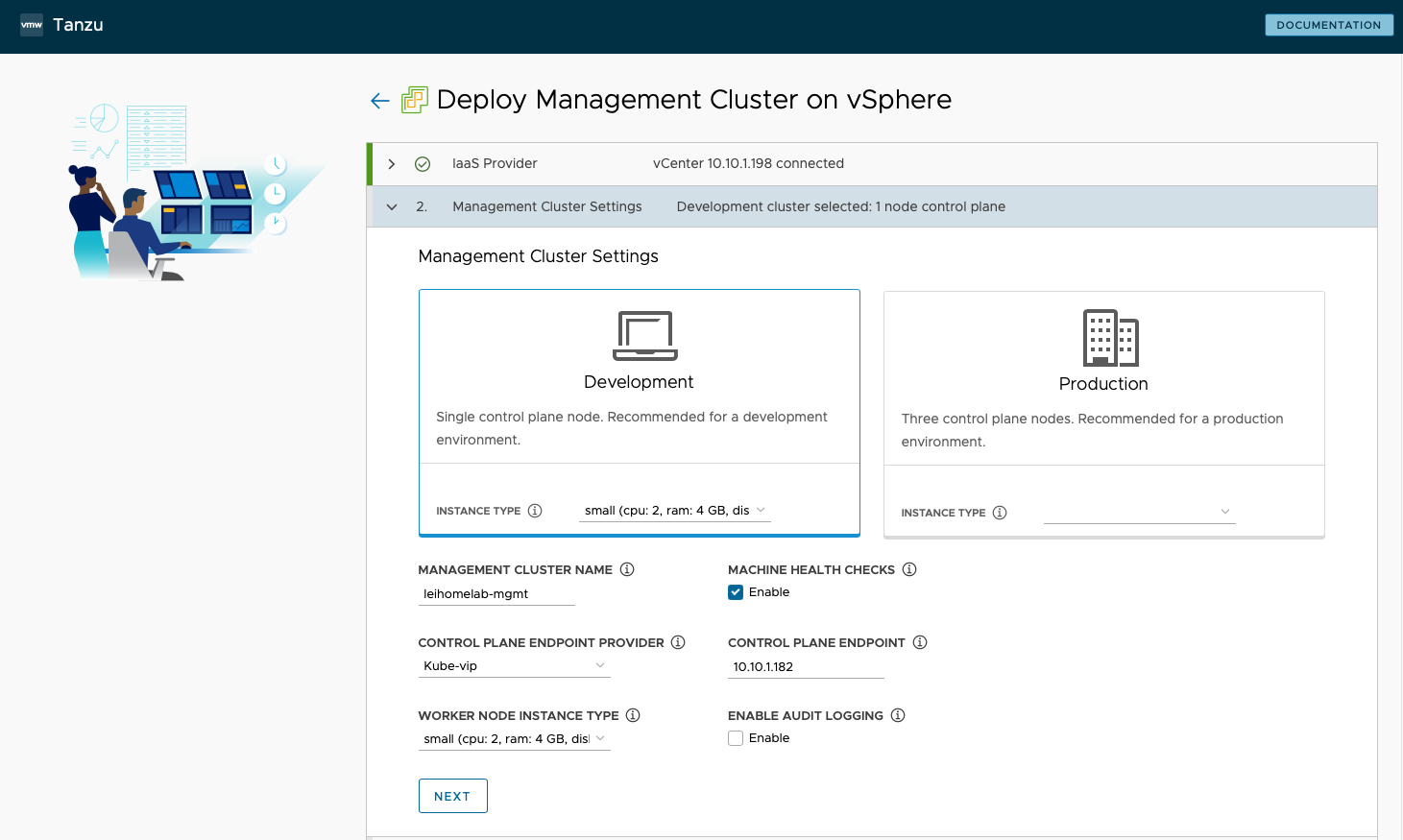
- VMware NSX Advanced Load Balancer 和 Metadata 部分,都禁用不选择。
- 在第五步 Resource 中,指定部署到 VM Folder 为
/HomelabDC/vm/tkg,Datastore 为/HomelabDC/datastore/localnvme,Cluster、Hosts、and Resource Pools 选择TanzuCE这个资源池。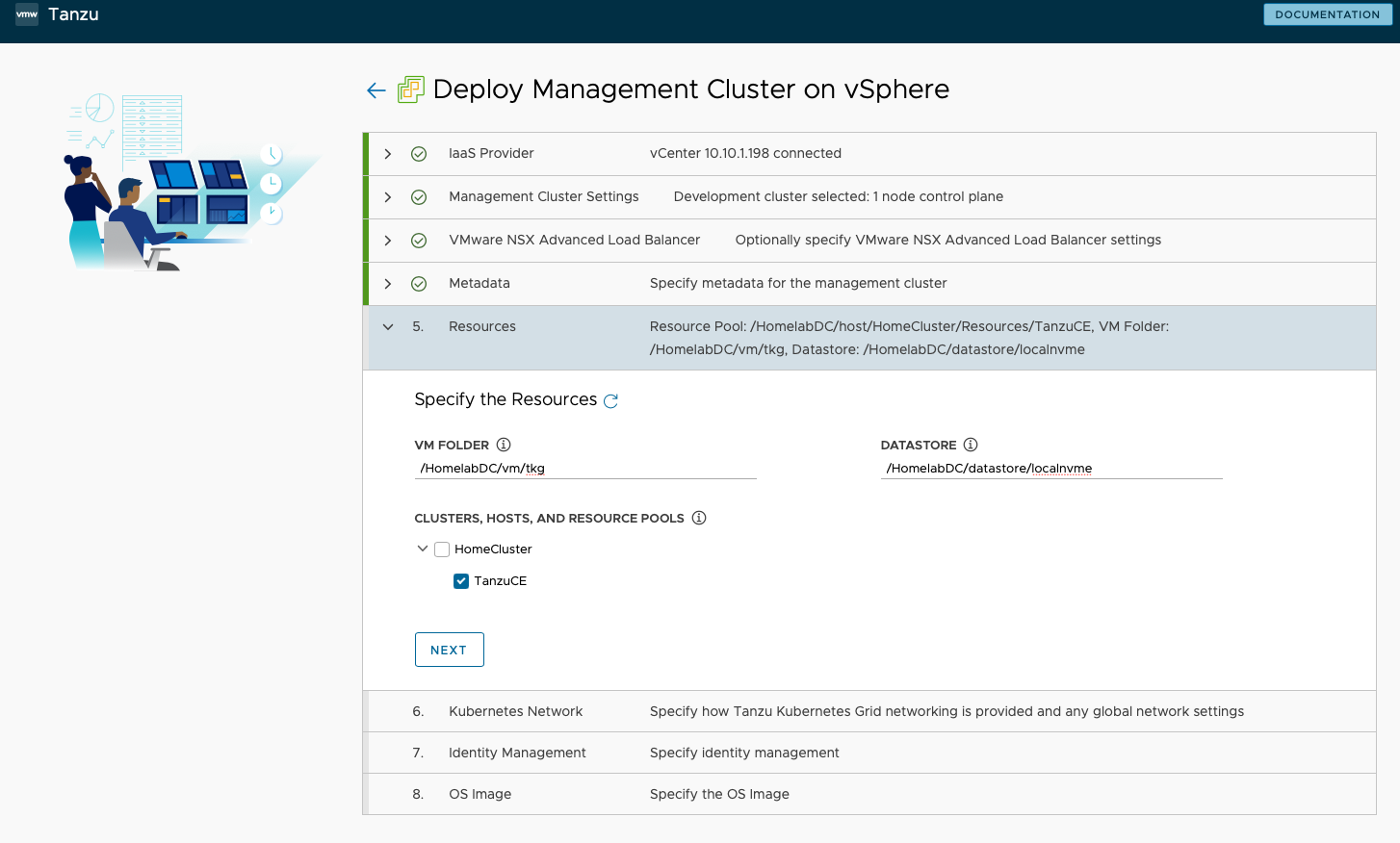
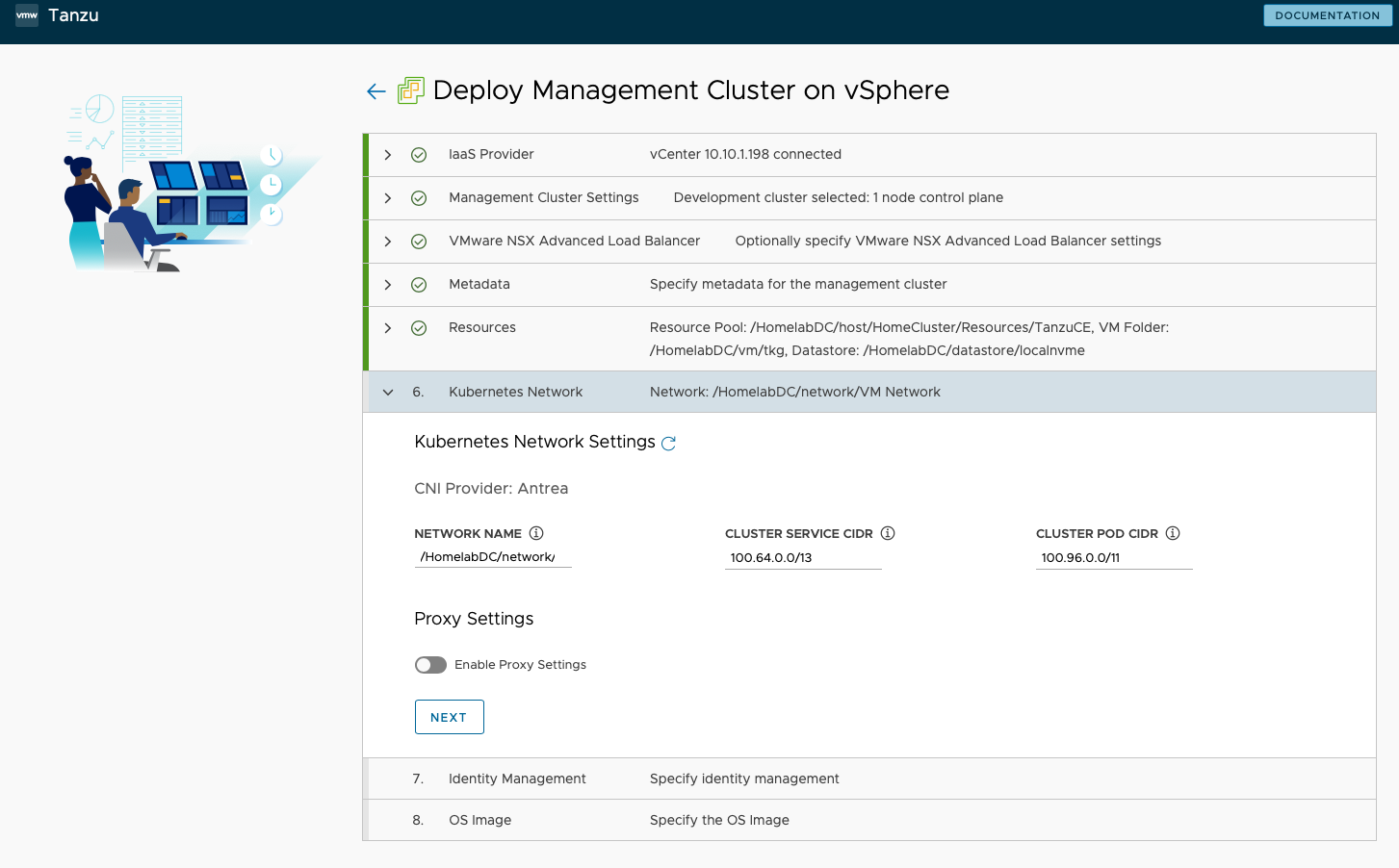
- Kubernetes Network 步骤中,配置没进行修改,保持默认。
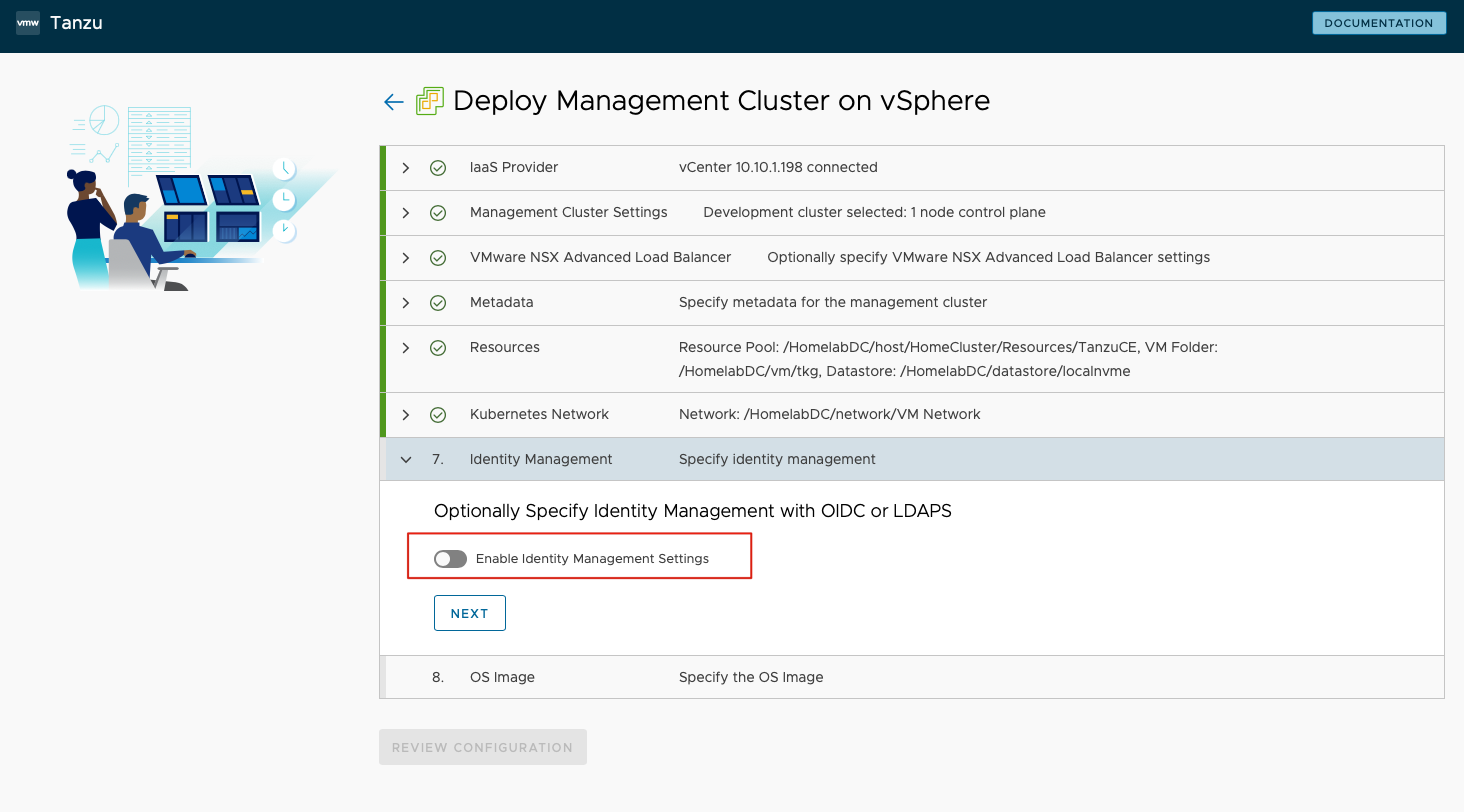
- Identity Management 步骤中,禁用 Identity Management Settings。
- OS image 步骤中,选择准备工作中已经导入的虚拟机模板 node 节点。
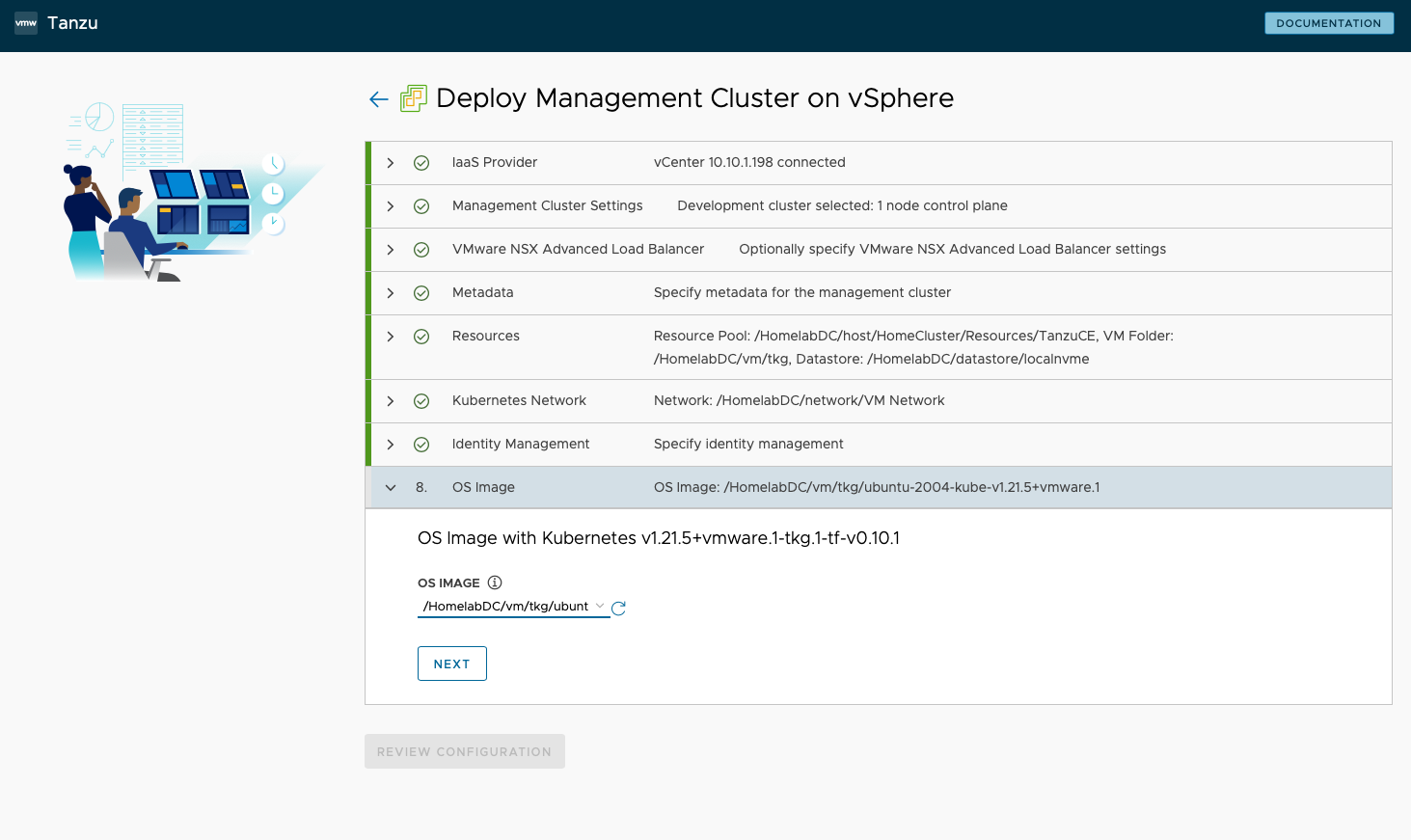
- 然后以上配置就完成了,Review 下 configuration 之后,就进入了全自动的配置,大约半小时左右管理集群将会被自动部署完并且可以使用。
管理集群部署完成后,回到我的 Ubuntu 控制台上,执行命令:
## 查询下前面安装的管理集群
k10@tceconsole:~$ tanzu management-cluster get
NAME NAMESPACE STATUS CONTROLPLANE WORKERS KUBERNETES ROLES
leihome tkg-system running 1/1 1/1 v1.21.5+vmware.1 management
Details:
NAME READY SEVERITY REASON SINCE MESSAGE
/leihome True 8d
├─ClusterInfrastructure - VSphereCluster/leihome True 8d
├─ControlPlane - KubeadmControlPlane/leihome-control-plane True 8d
│ └─Machine/leihome-control-plane-2mz2v True 8d
└─Workers
└─MachineDeployment/leihome-md-0
└─Machine/leihome-md-0-6f69758844-zpfsj True 8d
Providers:
NAMESPACE NAME TYPE PROVIDERNAME VERSION WATCHNAMESPACE
capi-kubeadm-bootstrap-system bootstrap-kubeadm BootstrapProvider kubeadm v0.3.23
capi-kubeadm-control-plane-system control-plane-kubeadm ControlPlaneProvider kubeadm v0.3.23
capi-system cluster-api CoreProvider cluster-api v0.3.23
capv-system infrastructure-vsphere InfrastructureProvider vsphere v0.7.10
## 获取 kubectl 的管理权限
k10@tceconsole:~$ tanzu management-cluster kubeconfig get leihome --admin
Credentials of cluster 'leihome' have been saved
You can now access the cluster by running 'kubectl config use-context leihome-admin@leihome'
## 试下 kubectl
k10@tceconsole:~$ kubectl get node
NAME STATUS ROLES AGE VERSION
leihome-control-plane-2mz2v Ready control-plane,master 8d v1.21.5+vmware.1
leihome-md-0-6f69758844-zpfsj Ready <none> 8d v1.21.5+vmware.1
这样,管理集群就全部完成了,这时候,回到 vCenter 上,也能够看到 2 台对应的 node 虚拟机。
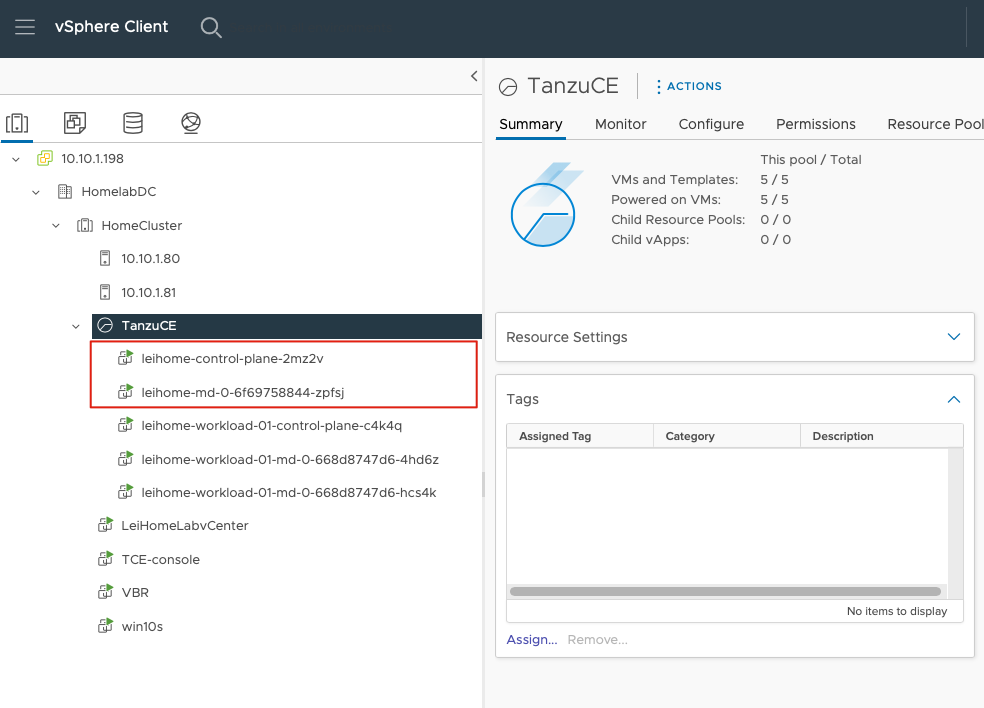
部署 Workload 集群
在管理集群部署完成后,以上的集群配置会以 yaml 文件自动保存在~/.config/tanzu/tkg/clusterconfigs/目录下,部署 Workload 集群的方法非常简单,只需要利用自动生成的管理集群的 yaml 文件,稍加修改,即可使用。
通过以下命令,先创建一份并修改用于部署 Workload 集群的 yaml 文件:
k10@tceconsole:~$ cp ~/.config/tanzu/tkg/clusterconfigs/pkwmre6kuu.yaml ~/.config/tanzu/tkg/clusterconfigs/workload1.yaml
k10@tceconsole:~$ vi ~/.config/tanzu/tkg/clusterconfigs/workload1.yaml
修改文件中以下字段:
CLUSTER_NAME: leihome-workload-01
VSPHERE_CONTROL_PLANE_ENDPOINT: 10.10.1.191
VSPHERE_WORKER_MEM_MIB: "8192"
其中CLUSTER_NAME是 Workload 集群的名称,我这里使用leihome-workload-01,VSPHERE_CONTROL_PLANE_ENDPOINT是这个 Workload 集群的 APIServer 的访问地址,设置为固定 IP 比较合适,我使用10.10.1.191,VSPHERE_WORKER_MEM_MIB是 Workload 集群的内存,我的环境中默认 Small 配置的 4GB 不太够用,我设置成了8192。
修改完成后,运行如下命令,就能自动部署 Workload 集群了。
k10@tceconsole:~$ tanzu cluster create leihome-workload-01 --file ~/.config/tanzu/tkg/clusterconfigs/workload1.yaml
大约 10 来分钟,Workload 集群就会部署完成,部署后和管理集群一样,默认配置为一个 Control Plane 和一个 Worker。我计划多运行几个应用程序,因此我用下面这条命令来增加 Worker Node:
k10@tceconsole:~$ tanzu cluster scale leihome-workload-01 --worker-machine-count=2
Successfully updated worker node machine deployment replica count for cluster leihome-workload-01
Workload cluster 'leihome-workload-01' is being scaled
Workload 集群部署完成后,和管理集群一样,需要获取下 Workload 集群的访问权限:
## 获取当前的 Workload 集群列表
k10@tceconsole:~$ tanzu cluster list
NAME NAMESPACE STATUS CONTROLPLANE WORKERS KUBERNETES ROLES PLAN
leihome-workload-01 default running 1/1 2/2 v1.21.5+vmware.1 <none> dev
## 获取 leihome-workload-01 这个 Workload 集群的访问权限
k10@tceconsole:~$ tanzu cluster kubeconfig get leihome-workload-01 --admin
Credentials of cluster 'leihome-workload-01' have been saved
You can now access the cluster by running 'kubectl config use-context leihome-workload-01-admin@leihome-workload-01'
## 用 kubectl 查下当前的 context 清单
k10@tceconsole:~$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* leihome-admin@leihome leihome leihome-admin
leihome-workload-01-admin@leihome-workload-01 leihome-workload-01 leihome-workload-01-admin
## 用 kubectl 命令切换下集群,开始使用部署出来的集群
k10@tceconsole:~$ kubectl config use-context leihome-workload-01-admin@leihome-workload-01
Switched to context "leihome-workload-01-admin@leihome-workload-01".
## 获取下 node
k10@tceconsole:~$ kubectl get node
NAME STATUS ROLES AGE VERSION
leihome-workload-01-control-plane-c4k4q Ready control-plane,master 7d18h v1.21.5+vmware.1
leihome-workload-01-md-0-668d8747d6-4hd6z Ready <none> 7d18h v1.21.5+vmware.1
leihome-workload-01-md-0-668d8747d6-hcs4k Ready <none> 7d18h v1.21.5+vmware.1
回到 vCenter 中,可以看到 3 台 Workload Node 虚拟机已经运行起来了。
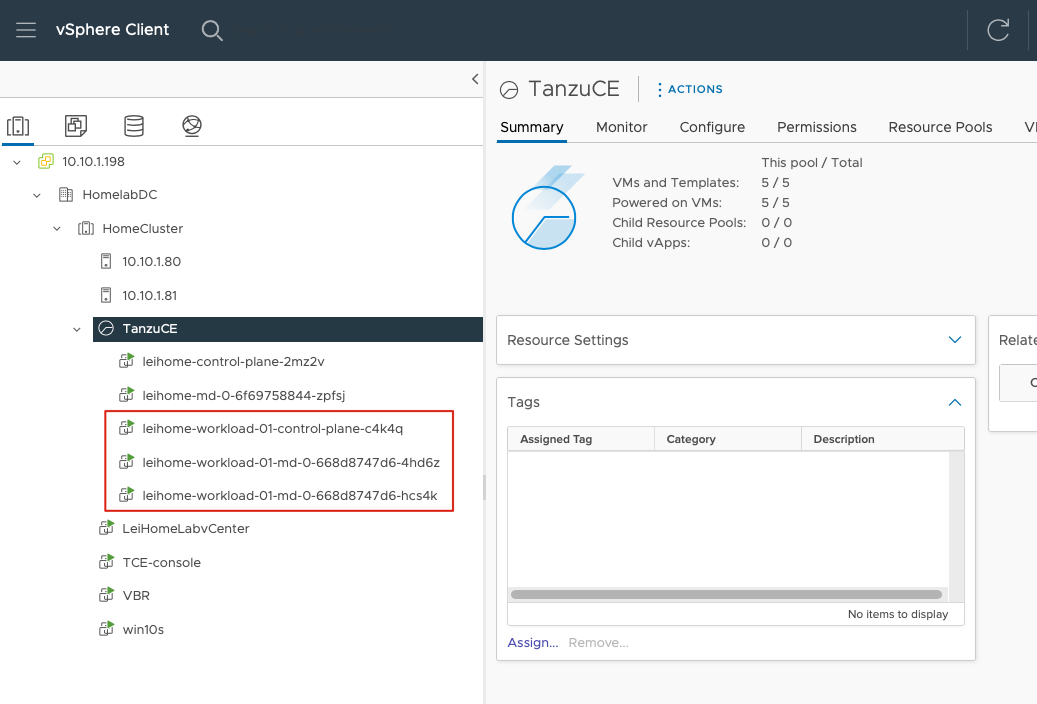
以上过程,Kubernetes 集群的计算资源就已经算是配置完成了。
存储资源配置
Tanzu 集群可以通过 vSphere CSI 使用 vSphere 7.0 上的 datastore 存放持久化数据,但是默认情况下并没有自动将 datastore 和 Tanzu 集群关联,这时候我通过下面这个 yaml 文件,将 datastore 的访问开放给 Workload。
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: standard
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: csi.vsphere.vmware.com
parameters:
datastoreurl: ds:///vmfs/volumes/622a19d3-91aee82b-59df-1c697aafcbf9/
其中最下面一行 datastoreurl 可以通过 vCenter 中 datastore 的 summary 中的地址获取,如图:
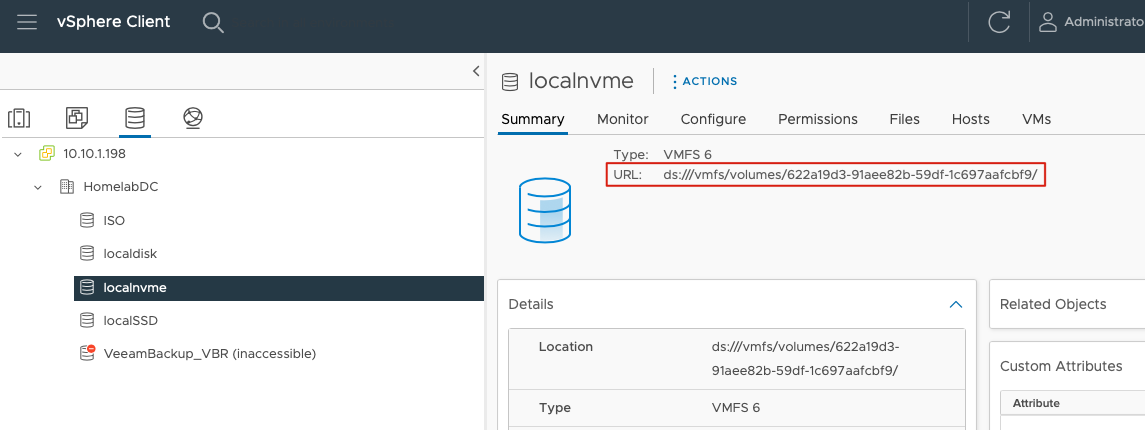
配置这个新的 StorageClass,并取消原来 default 的 storage Class 作为默认 Storage Class:
## 添加新的 Storage Class,连接 vSphere 上的 Datastore
k10@tceconsole:~$ kubectl apply -f ~/storage/localnvme.yaml
## 取消原来自动配上的 Hostpath 作为默认 Storage Class,当然也可以直接删除掉 default 的 storage class
k10@tceconsole:~$ kubectl patch storageclass default -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
## 用 kubectl 查询下目前的 sc 状况
k10@tceconsole:~$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
default csi.vsphere.vmware.com Delete Immediate true 7d19h
standard (default) csi.vsphere.vmware.com Delete Immediate false 7d18h
开个测试 demo 应用试下环境
这个小 demo 很简单,就是个 alpine Linux,挂一个数据目录/data,这个 data 目录实际上就会映射至 vSphere 的 Datastore 中,分配一个 vmdk 文件。关于这个 vmdk 文件,我先卖个关子,在下期推送中详细讨论。
小 Demo 的 yaml:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: demo-pvc
labels:
app: demo
pvc: demo
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-app
labels:
app: demo
spec:
replicas: 1
selector:
matchLabels:
app: demo
template:
metadata:
labels:
app: demo
spec:
containers:
- name: demo-container
image: alpine:3.7
resources:
requests:
memory: 256Mi
cpu: 100m
command: ["tail"]
args: ["-f", "/dev/null"]
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
persistentVolumeClaim:
claimName: demo-pvc
创建过程很简单,下面 2 条命令即可,创建完成后,拷贝个文件进持久数据卷试试:
k10@tceconsole:~$ kubectl create ns leihomedemo
k10@tceconsole:~$ kubectl apply -n leihomedemo -f ~/demo/demoapp.yaml
k10@tceconsole:~$ kubectl cp mytest leihomedemo/demo-app-696f676d47-dsbcr:/data/
k10@tceconsole:~$ kubectl exec --namespace=leihomedemo demo-app-696f676d47-dsbcr -- ls -l /data
total 24
drwx------ 2 root root 16384 Mar 12 14:01 lost+found
-rw-rw-r-- 1 1000 117 13 Mar 12 14:33 mytest
一切正常,环境完美运行。
安装配置 K10
安装 K10
安装 K10 前,我准备了一台 VBR v11a 的 Windows 服务器和一台 Minio S3 的对象存储,用于存放 K10 的备份数据。
K10 的安装和常规部署没任何区别,在安装前还是惯例运行下 Pre-flight 脚本检查环境:
k10@tceconsole:~$ curl https://docs.kasten.io/tools/k10_primer.sh | bash
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7045 100 7045 0 0 918 0 0:00:07 0:00:07 --:--:-- 1757
Namespace option not provided, using default namespace
Checking for tools
--> Found kubectl
--> Found helm
Checking if the Kasten Helm repo is present
--> The Kasten Helm repo was found
Checking for required Helm version (>= v3.0.0)
--> No Tiller needed with Helm v3.4.1
K10Primer image
--> Using Image (gcr.io/kasten-images/k10tools:4.5.11) to run test
Checking access to the Kubernetes context leihome-workload-01-admin@leihome-workload-01
--> Able to access the default Kubernetes namespace
K10 Kanister tools image
--> Using Kanister tools image (ghcr.io/kanisterio/kanister-tools:0.74.0) to run test
Running K10Primer Job in cluster with command-
./k10tools primer
serviceaccount/k10-primer created
clusterrolebinding.rbac.authorization.k8s.io/k10-primer created
job.batch/k10primer created
Waiting for pod k10primer-b5nf9 to be ready - ContainerCreating
Pod Ready!
I0319 05:28:41.931353 8 request.go:665] Waited for 1.043641473s due to client-side throttling, not priority and fairness, request: GET:https://100.64.0.1:443/apis/scheduling.k8s.io/v1beta1
Kubernetes Version Check:
Valid kubernetes version (v1.21.5+vmware.1) - OK
RBAC Check:
Kubernetes RBAC is enabled - OK
Aggregated Layer Check:
The Kubernetes Aggregated Layer is enabled - OK
W0319 05:28:42.188135 8 warnings.go:70] storage.k8s.io/v1beta1 CSIDriver is deprecated in v1.19+, unavailable in v1.22+; use storage.k8s.io/v1 CSIDriver
CSI Capabilities Check:
VolumeSnapshot CRD-based APIs are not installed - Error
Validating Provisioners:
csi.vsphere.vmware.com:
Storage Classes:
default
K10 supports the vSphere CSI driver natively. Creation of a K10 infrastucture profile is required.
Valid Storage Class - OK
isonfs
K10 supports the vSphere CSI driver natively. Creation of a K10 infrastucture profile is required.
Valid Storage Class - OK
standard
K10 supports the vSphere CSI driver natively. Creation of a K10 infrastucture profile is required.
Valid Storage Class - OK
Validate Generic Volume Snapshot:
Pod Created successfully - OK
GVS Backup command executed successfully - OK
Pod deleted successfully - OK
serviceaccount "k10-primer" deleted
clusterrolebinding.rbac.authorization.k8s.io "k10-primer" deleted
job.batch "k10primer" deleted
以上可以看到其中 CSI Capabilities Check 出现了个 Error,这个没关系,因为是使用 vSphere CSI,快照部分功能是利用 vSphere 源生的 vmdk 快照实现,因此在集群里我并没有安装 VolumeSnapshotClass。
安装 K10 还是老方法,官网手册中的可以直接使用,而我这边还是依旧使用 ccr.ccs.tencentyun.com/kasten 这个镜像库:
k10@tceconsole:~$ helm repo add kasten https://charts.kasten.io/
k10@tceconsole:~$ helm repo update
k10@tceconsole:~$ helm install k10 kasten/k10 \
--namespace=kasten-io \
--set global.persistence.storageClass=standard \
--set global.airgapped.repository=ccr.ccs.tencentyun.com/kasten \
--set metering.mode=airgap
## 通过 Nodeport 暴露 k10 图形界面访问
k10@tceconsole:~$ kubectl expose -n kasten-io deployment gateway --type=NodePort --name=gateway-nodeport-svc --port=8000
等待 10 来分钟之后,我的 K10 就能通过 http://10.10.1.14:32080/k10/#/进行访问了。
k10 配置 vCenter 和 VBR
进入 K10 主页后,在 Settings 中找到 Location Profile,首先需要添加一个 S3 对象存储作为主备份存储,就算我有 VBR 的存储库,这个都不能少。如下图配置非常简单:
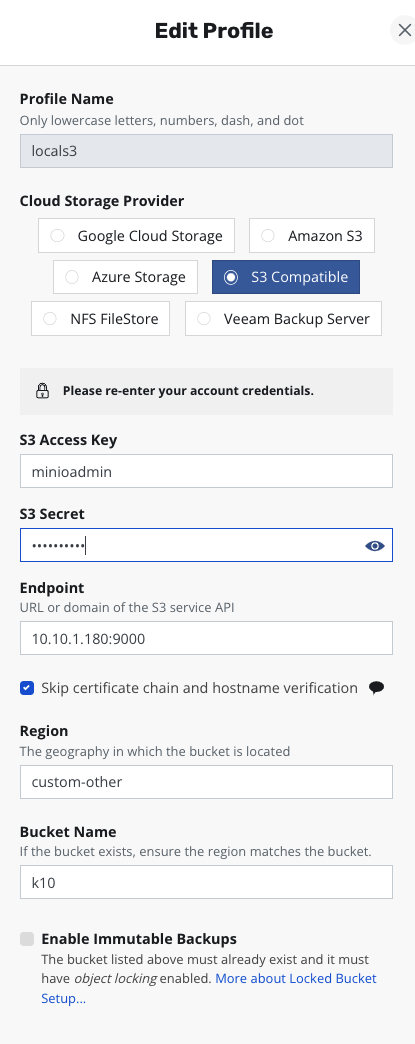
再来添加一个 VBR 的 Repository,用于 vmdk 数据备份存储,也就是 pvc 的备份。
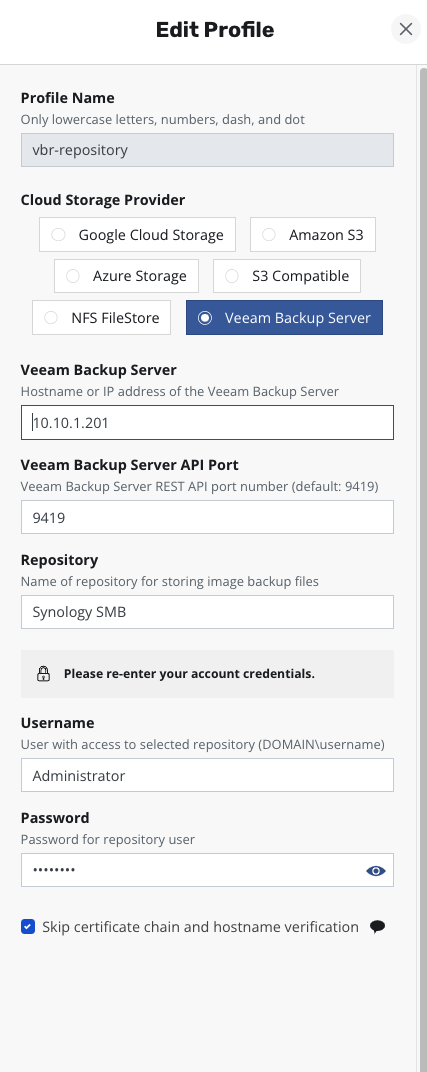
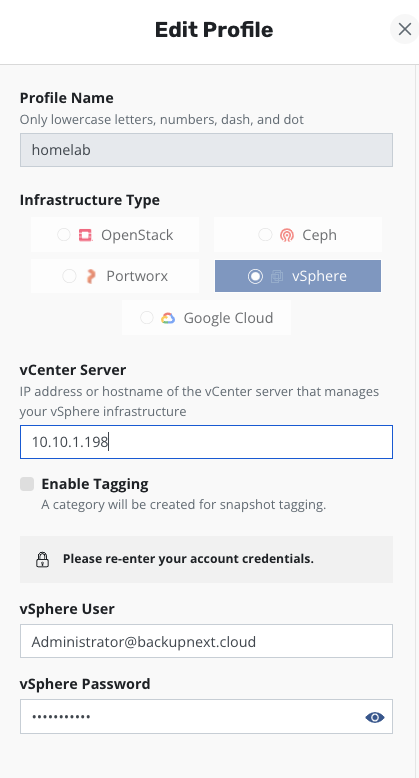
在 Location Profile 下面,找到 Infrastructure,使用 New Profile 按钮新增一个 vCenter 的连接,配置信息非常简单,和任何设备添加 vCenter 几乎没区别,IP 地址、用户名、密码,3 要素。
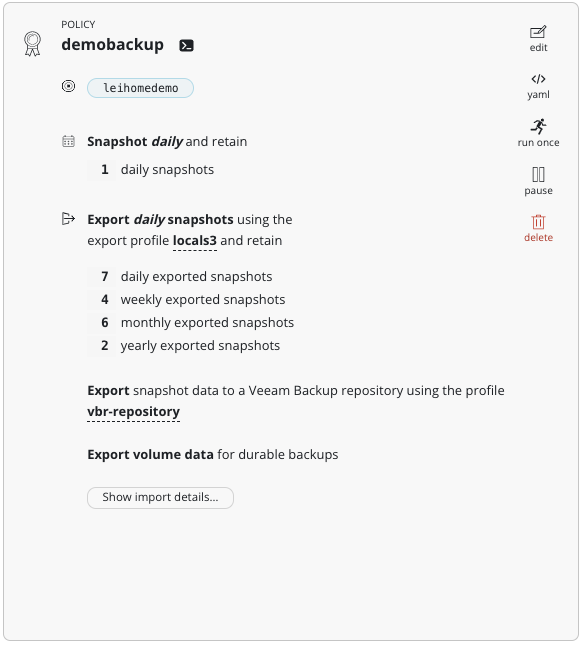
接下来,就可以进行备份策略的配置了。备份策略和其他 Kubernetes 平台 K10 的备份策略稍有不同,在 Snapshot Retention 上,可以看到 K10 自动感知到这是 VMware 平台,给出了 VMware 平台中 Snapshot 保留的最佳实践,建议不能超过 3 个 Snapshot。因此如下图,我将 Snapshot 设置为 1。在 Export Location Profile 中,可以选择 Minio S3 对象存储作为第一级备份 Export 目标,此处 VBR 的 Location Profile 不可选。
在这个Enable Backups via Snapshot Exports之后,会有个新增的选项Export snapshot data to a Veeam Backup Server repository,勾选这个选项后,可以选择 Veeam Backup Location Profile。
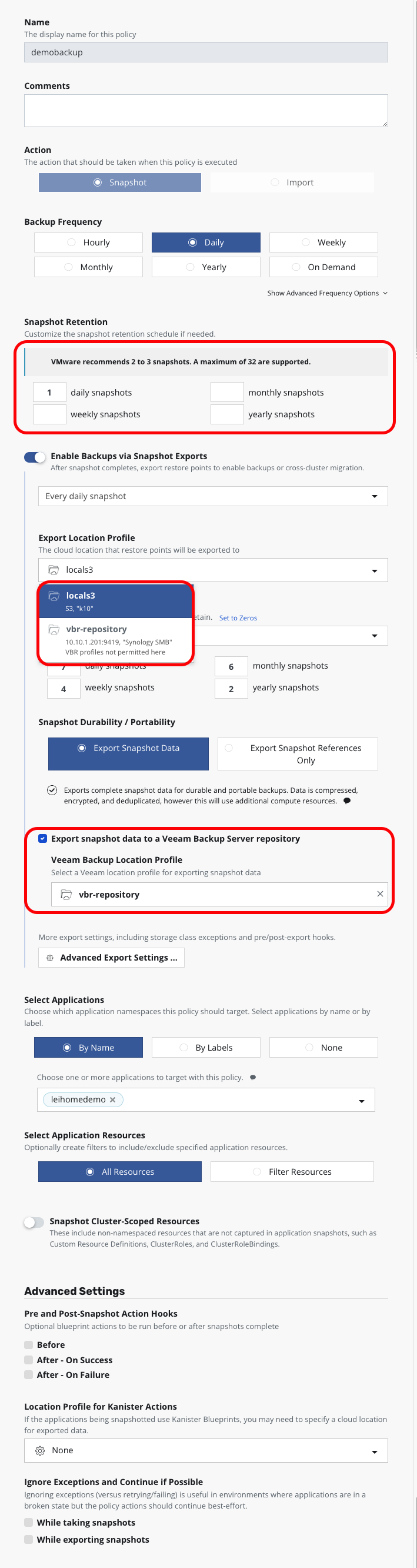
其他配置没有什么特别,这样配置后的 Policy 如下:
备份自动运行后,可以从 Dashboard 进入查看到详细的备份 Action 详情,其中 VBR 的导出部分由 Kanister 完成:

而在 VBR 中,可以看到 K10 的 Policy 和 K10 的备份存档也已经出现:
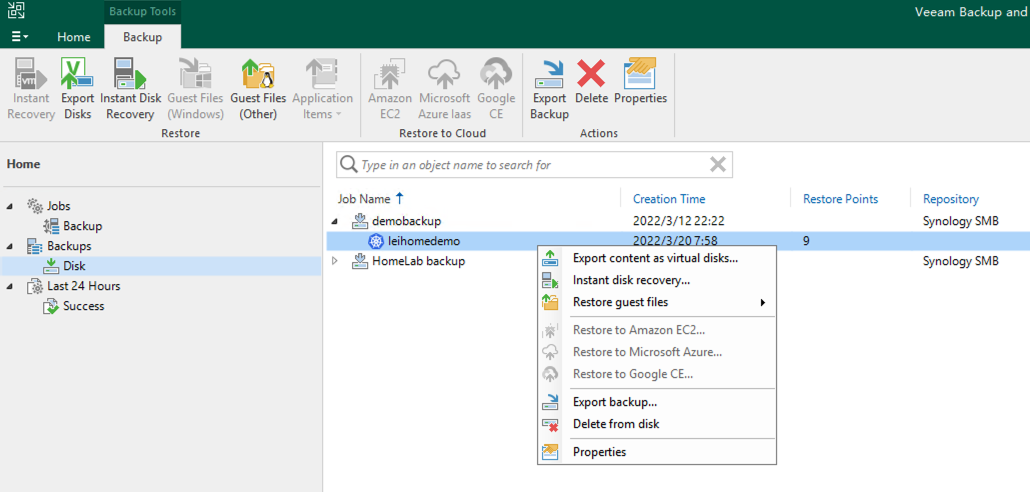
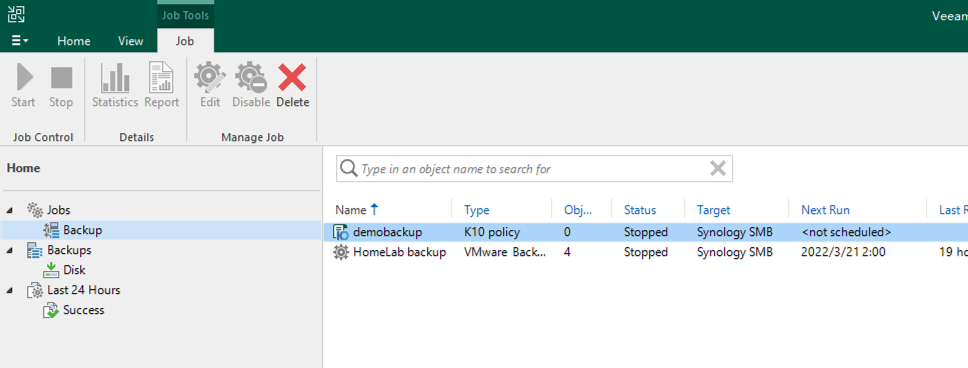
关于 VBR 中 K10 的操作,可以参考 Veeam 官方的手册,已经在官网上线。
最后
到目前为止,整个环境资源消耗:
| 虚拟机 | 用途 | CPU | 内存 |
|---|---|---|---|
| vCenter | vCenter | 2vCPU | 12GB |
| TCEconsole | Tanzu 控制台 | 2vCPU | 8GB |
| leihome-control-plane-2mz2v | TCE 管理集群控制节点 | 2vCPU | 4GB |
| leihome-md-0-6f69758844-zpfsj | TCE 管理集群工作节点 | 2vCPU | 4GB |
| leihome-workload-01-control-plane-c4k4q | TCE 工作集群控制节点 | 2vCPU | 4GB |
| leihome-workload-01-md-0-668d8747d6-4hd6z | TCE 工作集群工作节点 | 2vCPU | 8GB |
| leihome-workload-01-md-0-668d8747d6-hcs4k | TCE 工作集群工作节点 | 2vCPU | 8GB |
| VBR | VBR | 4vCPU | 8GB |
| 总计 | 18vCPU | 56GB | |
还没超过我的 NUC11 总内存,一台 NUC11 跑这么个环境绰绰有余啦。




